Yulia NudelmanNeural Network Fundamentals: Understanding the Core ComponentsOnce upon a time, there lived the wisest and most powerful creatures in the world, known as the “Neurons.” The Neurons could solve any…Feb 14, 2023Feb 14, 2023
Yulia NudelmanNamed Entity Recognition with FlairTrain custom Named Entity Recognition (NER) model with the Flair NLP framework.Aug 22, 20221Aug 22, 20221
Yulia NudelmanHow to Build Named Entity Training Dataset for NER Task (Part 1)Building a Named Entity Classification PipelineAug 26, 2021Aug 26, 2021
Yulia NudelmanBuild a RoBERTa Model from ScratchIn this article, we will build a pre-trained transformer model FashionBERT using the Hugging Face models.Feb 18, 2021Feb 18, 2021
Yulia NudelmanExtract Table from PDF with PythonFind and extract table from PDF file with pdfplumber library.Feb 10, 2021Feb 10, 2021
Yulia NudelmanBuild a Corpus for NLP Models from Wikipedia dump fileAll NLP (Natural Language Processing) tasks need text data for training. One of the largest text data sources is Wikipedia that offers…Dec 31, 20201Dec 31, 20201
Yulia NudelmanNews Search Engine with Elasticsearch and PythonHow to build a simple search engine with Elasticsearch and PythonDec 18, 2020Dec 18, 2020
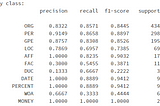
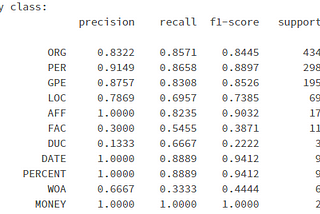
Yulia NudelmanMulti-Class Hebrew Text Classification with Scikit-LearnIn this article, we will classify women’s clothing product descriptions into 13 predefined classes. All descriptions are in Hebrew.Nov 29, 20201Nov 29, 20201